
Claude 4: Anthropic's first model built for agents, not just conversations
On May 22, 2025, Anthropic launched Claude Opus 4 and Sonnet 4 — the first Claude generation explicitly designed for sustained multi-hour autonomous work. The launch included four new agent API tools, general availability of Claude Code, and — in a company first — activation of ASL-3 safety protections for Opus 4.

研究速览
On May 22, 2025, Anthropic released Claude Opus 4 and Claude Sonnet 4 — the first generation of models the company has explicitly designed to run for hours without a human in the loop.1 The release is a meaningful pivot: previous Claude generations were optimized for single interactions; the Claude 4 family is calibrated for sustained autonomous work on complex, multi-step tasks. Alongside the models, Anthropic shipped four new API tools for agent developers and — in a first for the company — activated its AI Safety Level 3 (ASL-3) protections for Opus 4, publicly acknowledging that it could not rule out the model approaching a dangerous-capability threshold.
What the models actually do
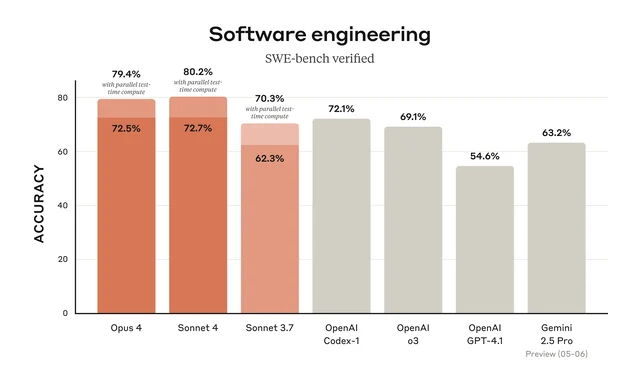
Claude Opus 4 is Anthropic's most capable model at launch and, by its own benchmarks, the best coding model available at the time. It scores 72.5% on SWE-bench Verified — a standard benchmark for real software engineering tasks — and 43.2% on Terminal-bench, a test of long-horizon command-line operation.1 Those numbers come without extended thinking; with it, the model's performance on reasoning benchmarks climbs further (GPQA Diamond reaches 82.3%, AIME 2025 hits 80.1%).
The benchmark figures matter less than what they represent: Opus 4 can maintain focused work across thousands of steps. In one example cited by Anthropic, the Japanese e-commerce company Rakuten ran the model through an open-source refactor that took seven hours and required sustained performance throughout.1 Earlier models — including Claude 3.7 Sonnet, which was strong in short bursts — would drift on tasks of that length. Opus 4 largely does not.
Claude Sonnet 4 trades some capability ceiling for speed and cost. It scores 72.7% on SWE-bench Verified — marginally higher than Opus 4 on that particular benchmark — while running faster and at one-fifth the price ($3/$15 per million tokens input/output vs. Opus 4's $15/$75).1 GitHub announced it would use Sonnet 4 to power the new coding agent in GitHub Copilot; Manus cited better instruction-following and aesthetic output; Sourcegraph and Augment Code reported that it keeps context longer and makes more surgical code edits than previous Sonnet versions.
Both models are hybrid: they can respond instantly or, when given more compute budget, enter extended thinking and work through a problem before producing output. Extended thinking now also interleaves with tool use — Opus 4 and Sonnet 4 can search the web mid-reasoning, check an API, or read a file, then continue thinking with that new information before finalizing an answer.1 That interleaving is new to the Claude 4 generation; prior versions couldn't alternate between reasoning tokens and tool calls.
Memory, shortcuts, and the agent behavior gap
Two behavioral changes deserve attention beyond benchmark numbers.
First, memory. When developers give Claude local file access, Opus 4 can now create and maintain "memory files" — plain text documents it writes to and reads from over a session to track what it has learned. The model uses these files naturally: during a well-publicized demonstration of Opus 4 playing Pokémon Red, it produced a "Navigation Guide" that it updated and consulted as it moved through the game.1 This is not a new memory architecture; it is the same model using tools more deliberately. But it shows a qualitative shift in how the model manages long tasks, rather than holding everything in context and hoping the window is large enough.
Second, shortcut reduction. Anthropic reports that Claude 4 models are 65% less likely to take shortcuts or exploit loopholes to complete tasks than Sonnet 3.7, specifically on agentic tasks where taking the easy path is a genuine temptation.1 This matters more for autonomous agents than for single-turn chat: a model writing code for a person can be corrected if it games the test suite; a model running unattended for seven hours cannot. The reduction was measured on tasks specifically selected because they are "particularly susceptible to shortcuts and loopholes" — meaning Anthropic is aware of and testing for this class of failure.
Four new API tools shipped the same day
Alongside the models, Anthropic released four agent-building primitives in public beta, all available immediately on the API and on Amazon Bedrock and Vertex AI.2
| Tool | What it does |
|---|---|
| Code execution | Runs Python in a sandboxed container; Claude can generate, execute, and iterate on code within a single API call |
| MCP connector | Connects to any remote Model Context Protocol server without custom client code; Anthropic handles authentication and tool discovery |
| Files API | Stores documents server-side so they can be referenced across sessions without re-uploading |
| Extended prompt caching | Raises the cache TTL from 5 minutes to 1 hour; can cut costs by up to 90% and latency by up to 85% on long repeated prompts |
The code execution tool turns Claude from a code-writing assistant into a data analyst that can run its own code, observe the results, and adjust — the difference between a model that proposes an analysis plan and one that can execute and verify it. The MCP connector matters because it standardizes how agents access external systems: instead of developers writing bespoke integration logic for each tool, they add a server URL to the API request and Anthropic handles the rest.
正在加载内容卡片…
ASL-3: the first time Anthropic activated its highest safety tier
正在加载内容卡片…
The safety dimension of this release is harder to characterize cleanly, but probably more significant than the benchmarks.
When Anthropic published its Responsible Scaling Policy (RSP) in 2023, it defined a ladder of AI Safety Levels: ASL-2 covered all models deployed until now, requiring models to refuse dangerous CBRN-related requests and resist opportunistic weight-theft attacks. ASL-3 is the tier above — designed for models whose CBRN capabilities could provide "serious uplift" to non-state actors attempting to develop weapons of mass destruction. Reaching ASL-3 means a model is either above that capability threshold, or close enough that Anthropic cannot confidently rule it out.
For Opus 4, Anthropic activated ASL-3 protections while explicitly stating it has not confirmed that the model exceeds the dangerous-capability threshold.3 The reasoning is a precautionary one: Opus 4's CBRN knowledge and reasoning have improved enough that ruling out the threshold would require "more detailed research," and the RSP allows activating higher protections before finishing that evaluation. Anthropic confirmed that Sonnet 4 does not require ASL-3, and that Opus 4 does not require ASL-4.
What ASL-3 actually requires in practice divides into two categories:
Deployment measures target misuse. A constitutional classifier inspects inputs and outputs in real time, trained specifically on harmful and benign CBRN-related prompts. The classifier is designed to block "end-to-end" CBRN assistance and resist "universal jailbreaks" — systematic attacks that could reliably extract dangerous information at scale — while leaving unobstructed queries for publicly available single facts. Anthropic also runs an offline detection system and a vulnerability disclosure (bug bounty) program specifically targeting classifier weaknesses.3
Security measures target model weight theft. The new standard is designed to defend against "sophisticated non-state actors" — one tier below nation-state adversaries with entirely novel attack chains. Over 100 security controls cover the path from initial compromise through lateral movement to data exfiltration, including two-party authorization for weight access and export bandwidth controls. The bandwidth throttling on secure compute environments is particularly interesting: because model weights are very large, limiting outbound bandwidth creates an asymmetric defensive advantage that is hard to circumvent without slowing the exfiltration to an easily detectable rate.3
Claude Code goes generally available
The Claude 4 launch also marked the general availability of Claude Code — previously in research preview — with several additions that push it beyond a terminal tool.1
Beta extensions for VS Code and JetBrains display Claude's proposed edits inline in open files, rather than as a diff in the terminal. A new SDK lets developers build their own agents using the same core agent as Claude Code. And a GitHub Actions integration — Claude Code on GitHub, in beta — lets developers tag Claude on pull requests to fix CI errors, respond to reviewer comments, or modify code in the repository directly.
Together these position Claude Code as a platform rather than a product: the SDK and GitHub integration mean teams can wire Claude Code into their existing review and CI pipelines without switching development environments.
What shifts with this generation
Claude 4 is not the first capable model to run agentic tasks, and it is not the last. But the combination of what shipped on May 22, 2025 — sustained long-horizon performance, shortcut reduction, interleaved reasoning and tool use, a four-tool agent API, and the ASL-3 activation — marks a qualitative change in how Anthropic is positioning Claude.
The previous generation optimized for the single-turn interaction: smart, careful, good in context windows. Claude 4 optimizes for the extended autonomous loop: staying on task, managing its own knowledge over time, resisting the temptation to cheat, and doing so safely enough that Anthropic formally raised its internal safety classification. That last point is the most unusual: a company publicly acknowledging that its own product might be near a dangerous capability threshold, rather than waiting until the threshold is confirmed, is still uncommon in the industry.
Whether the ASL-3 deployment controls are actually sufficient is a separate question — one that would require access to the red-teaming results and adversarial evaluation data that Anthropic has not published in full. The precautionary framing is honest, but "we can't rule it out, so we're treating it as if it crossed the line" is not the same as "we verified these controls are adequate." That gap is worth watching as the model continues to be deployed.
围绕这条内容继续补充观点或上下文。